
基于docker实现Redis哨兵机制
2020-07-15 17:13:03
1241
技术小虫有点萌
技术小虫有点萌
今天咱们来聊一聊redis哨兵机制的实现。
今天讲的很简单,之前的三台主从已经实现了,不知道的小伙伴请参考Redis主从复制(基于docker)的配置和实现原理
What is reasonable is real; that which is real is reasonable.凡是先问为什么,为什么需要哨兵? 1.存在问题 Redis 的 主从复制 模式下,一旦 主节点 由于故障不能提供服务,需要手动将 从节点 晋升为 主节点,同时还要通知 客户端 更新 主节点地址,这种故障处理方式从一定程度上是无法接受的。Redis 2.8 以后提供了 Redis Sentinel 哨兵机制 来解决这个问题。 2.高可用 在 Redis 中,实现 高可用 的技术主要包括 持久化、复制、哨兵 和 集群,下面简单说明它们的作用,以及解决了什么样的问题: 持久化:持久化是 最简单的 高可用方法。它的主要作用是 数据备份,即将数据存储在 硬盘,保证数据不会因进程退出而丢失。 复制:复制是高可用 Redis 的基础,哨兵 和 集群 都是在 复制基础 上实现高可用的。复制主要实现了数据的多机备份以及对于读操作的负载均衡和简单的故障恢复。缺陷是故障恢复无法自动化、写操作无法负载均衡、存储能力受到单机的限制。 哨兵:在复制的基础上,哨兵实现了 自动化 的 故障恢复。缺陷是 写操作 无法 负载均衡,存储能力 受到 单机 的限制。 集群:通过集群,Redis 解决了 写操作 无法 负载均衡 以及 存储能力 受到 单机限制 的问题,实现了较为 完善 的 高可用方案。 3.主要功能 Sentinel 的主要功能包括 主节点存活检测、主从运行情况检测、自动故障转移 (failover)、主从切换。Redis 的 Sentinel 最小配置是 一主一从。 Redis 的 Sentinel 系统可以用来管理多个 Redis 服务器,该系统可以执行以下四个任务: 监控 Sentinel 会不断的检查 主服务器 和 从服务器 是否正常运行。 通知 当被监控的某个 Redis 服务器出现问题,Sentinel 通过 API 脚本 向 管理员 或者其他的 应用程序 发送通知。 自动故障转移 当 主节点 不能正常工作时,Sentinel 会开始一次 自动的 故障转移操作,它会将与 失效主节点 是 主从关系 的其中一个 从节点 升级为新的 主节点,并且将其他的 从节点 指向 新的主节点。 配置提供者 在 Redis Sentinel 模式下,客户端应用 在初始化时连接的是 Sentinel 节点集合,从中获取 主节点 的信息。
好了,废话不多说,直接开撸 先看一下三台服务器,都是启动状态
拷贝三份哨兵的配置文件;配置如下,三台的端口号分别是26379 2637 26372,依次修改即可,

# 哨兵sentinel实例运行的端口,默认26371
port 26371
# 哨兵sentinel的工作目录
dir "/data"
daemonize yes
protected-mode no
logfile "/var/log/redis/redis_26371.log"
# 哨兵sentinel监控的redis主节点的
## ip:主机ip地址
## port:哨兵端口号
## master-name:可以自己命名的主节点名字(只能由字母A-z、数字0-9 、这三个字符".-_"组成。)
## quorum:当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel myid e8c3e2d4ec0ee2cdf2ed672d7b65f4198985797b
# 当在Redis实例中开启了requirepass <foobared>,所有连接Redis实例的客户端都要提供密码。
# sentinel auth-pass <master-name> <password>
#sentinel auth-pass mymaster 123456
# 指定主节点应答哨兵sentinel的最大时间间隔,超过这个时间,哨兵主观上认为主节点下线,默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel deny-scripts-reconfig yes
# 指定了在发生failover主备切换时,最多可以有多少个slave同时对新的master进行同步。这个数字越小,完成failover所需的时间就越长;反之,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为1,来保证每次只有一个slave,处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel monitor mymaster 172.17.0.2 6379 2
# 故障转移的超时时间failover-timeout,默认三分钟,可以用在以下这些方面:
## 1. 同一个sentinel对同一个master两次failover之间的间隔时间。
## 2. 当一个slave从一个错误的master那里同步数据时开始,直到slave被纠正为从正确的master那里同步数据时结束。
## 3. 当想要取消一个正在进行的failover时所需要的时间。
## 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来同步数据了
# sentinel failover-timeout <master-name> <milliseconds>
sentinel config-epoch mymaster 0
# 当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本。一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
# 对于脚本的运行结果有以下规则:
## 1. 若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10。
## 2. 若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
## 3. 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
# sentinel notification-script <master-name> <script-path>
#sentinel notification-script mymaster /var/redis/notify.sh
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
#sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
配置文件准备完毕后开始启动docker ,其他两个对照改一下(也可以使用info命令查看状态)
guofu@guofu-Inspiron-3558 redis $ docker run --rm -d -p 26371:26371 --name srediss1 \
> -v /home/guofu/redis:/conf \
> -v /home/guofu/redis/log/redis:/var/log/redis \
> -v /home/guofu/redis/data26371:/data \
> redis
4ecf4222c6649ae9731b99befba6923314824af406ddbbcb93136ed72e12c08c
guofu@guofu-Inspiron-3558 redis $ docker exec -it 4ecf422 bash
root@4ecf4222c664:/data# /usr/local/bin/redis-sentinel /conf/rediss1.conf
启动完毕后,配置文件后面会追加一部分内容,相信大家都能看懂,一台主服务器,两台从服务,两台哨兵
在哨兵服务器下启动客户端查看相关信息,这里只截取一部分看一下
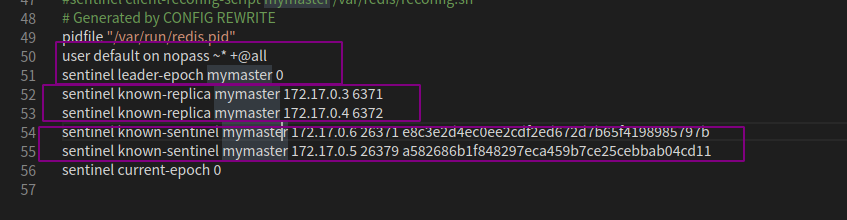
127.0.0.1:26379> info
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.17.0.2:16379,slaves=2,sentinels=3
127.0.0.1:26372> SENTINEL masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "172.17.0.2"
5) "port"
6) "6379"
127.0.0.1:26372> SENTINEL slaves mymaster
1) 1) "name"
2) "172.17.0.3:6371"
3) "ip"
4) "172.17.0.3"
5) "port"
6) "6371"
7) "runid"
2) 1) "name"
2) "172.17.0.4:6372"
3) "ip"
4) "172.17.0.4"
5) "port"
6) "6372"
7) "runid"
关闭主服务器查看效果
#关闭redis服务
redis-cli SHUTDOWN
guofu@guofu-Inspiron-3558 redis $ docker stop mredis
mredis
#哨兵机查看状态
127.0.0.1:26379> info
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.17.0.3:16371,slaves=2,sentinels=3
查看哨兵日志
24:X 15 Jul 2020 03:51:32.560 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
24:X 15 Jul 2020 03:51:32.560 # Redis version=6.0.5, bits=64, commit=00000000, modified=0, pid=24, just started
24:X 15 Jul 2020 03:51:32.560 # Configuration loaded
25:X 15 Jul 2020 03:51:32.568 * Running mode=sentinel, port=26372.
25:X 15 Jul 2020 03:51:32.568 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
25:X 15 Jul 2020 03:51:32.628 # Sentinel ID is da3d9af3ce0fb73048a93e4131829e8c6b726b03
25:X 15 Jul 2020 03:51:32.628 # +monitor master mymaster 172.17.0.2 16379 quorum 2
25:X 15 Jul 2020 03:51:32.630 * +sentinel sentinel e8c3e2d4ec0ee2cdf2ed672d7b65f4198985797b 172.17.0.6 26371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:51:32.717 # +new-epoch 140
25:X 15 Jul 2020 03:51:32.718 * +slave slave 172.17.0.4:16372 172.17.0.4 16372 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:51:32.761 * +slave slave 172.17.0.3:16371 172.17.0.3 16371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:51:33.453 * +sentinel sentinel 8a669db5246622e5e716ea7de2045dfb504a8ba6 172.17.0.5 26379 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:29.885 # +sdown master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:29.937 # +odown master mymaster 172.17.0.2 16379 #quorum 2/2
25:X 15 Jul 2020 03:57:29.938 # +new-epoch 141
25:X 15 Jul 2020 03:57:29.938 # +try-failover master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:29.980 # +vote-for-leader da3d9af3ce0fb73048a93e4131829e8c6b726b03 141
25:X 15 Jul 2020 03:57:30.059 # 8a669db5246622e5e716ea7de2045dfb504a8ba6 voted for da3d9af3ce0fb73048a93e4131829e8c6b726b03 141
25:X 15 Jul 2020 03:57:30.063 # +elected-leader master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.063 # +failover-state-select-slave master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.146 # +selected-slave slave 172.17.0.3:16371 172.17.0.3 16371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.147 * +failover-state-send-slaveof-noone slave 172.17.0.3:16371 172.17.0.3 16371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.202 * +failover-state-wait-promotion slave 172.17.0.3:16371 172.17.0.3 16371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.258 # +promoted-slave slave 172.17.0.3:16371 172.17.0.3 16371 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.258 # +failover-state-reconf-slaves master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:30.268 * +slave-reconf-sent slave 172.17.0.4:16372 172.17.0.4 16372 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:31.200 # -odown master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:31.267 * +slave-reconf-inprog slave 172.17.0.4:16372 172.17.0.4 16372 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:31.267 * +slave-reconf-done slave 172.17.0.4:16372 172.17.0.4 16372 @ mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:31.318 # +failover-end master mymaster 172.17.0.2 16379
25:X 15 Jul 2020 03:57:31.319 # +switch-master mymaster 172.17.0.2 16379 172.17.0.3 16371
25:X 15 Jul 2020 03:57:31.319 * +slave slave 172.17.0.4:16372 172.17.0.4 16372 @ mymaster 172.17.0.3 16371
25:X 15 Jul 2020 03:57:31.319 * +slave slave 172.17.0.2:16379 172.17.0.2 16379 @ mymaster 172.17.0.3 16371
25:X 15 Jul 2020 03:58:01.325 # +sdown slave 172.17.0.2:16379 172.17.0.2 16379 @ mymaster 172.17.0.3 16371
查看从服务器日志
24:S 15 Jul 2020 03:57:00.639 * Connecting to MASTER 172.17.0.2:16379
24:S 15 Jul 2020 03:57:00.640 * MASTER <-> REPLICA sync started
24:M 15 Jul 2020 03:57:30.202 * Discarding previously cached master state.
24:M 15 Jul 2020 03:57:30.202 # Setting secondary replication ID to 2dd8486ca81e0c4b2ad02d79213ad016a361d541, valid up to offset: 116114. New replication ID is f6357dfa90bfeaf2794bfc385c00145f00961960
24:M 15 Jul 2020 03:57:30.203 * MASTER MODE enabled (user request from 'id=8 addr=172.17.0.7:33859 fd=11 name=sentinel-da3d9af3-cmd age=358 idle=0 flags=x db=0 sub=0 psub=0 multi=4 qbuf=216 qbuf-free=32552 obl=45 oll=0 omem=0 events=r cmd=exec user=default')
24:M 15 Jul 2020 03:57:30.208 # CONFIG REWRITE executed with success.
24:M 15 Jul 2020 03:57:30.519 * Replica 172.17.0.4:16372 asks for synchronization
24:M 15 Jul 2020 03:57:30.519 * Partial resynchronization request from 172.17.0.4:16372 accepted. Sending 443 bytes of backlog starting from offset 116114.
通过客户端添加一个key 事实有一次证明。我们成功了。

相关推荐
phpstorm添加swoole语法提示
1801
2020-05-11

大佬们都说tcp有黏包的问题,tcp却说:我冤枉!
532
2023-03-02
视频直播技术真的很难吗?手把手带你实现直播技术(一)
1701
2021-01-18
同步与异步、阻塞与非阻塞傻傻分不清楚?你得从linux中的5种IO模型看起
754
2022-07-11
快速学习正则表达式,不用死记硬背,这里有份中文资源和互动学习网站
1538
2020-06-11
php安全之道的大略讲解和总结
3462
2020-07-23
不到40行代码教你如何利用php高效快速的爬取10w+网页数据
1519
2020-05-25
明明白白的聊一下什么是服务发现
449
2023-04-11
面试官又双叒叕问你TCP的三次握手和四次挥手?看这里!有图有真相!!
1258
2021-02-23
ChatGPT为什么这么火爆?这是一篇从入门到玩坏的教程
630
2023-02-09
go集成nacos配置中心并读取配置信息
375
2023-05-29
聊一聊进程、线程和协程以及线程的那些“锁“事
1046
2022-02-08
https你很熟?灵魂三连问之https安全在哪里?客户端如何验证https证书的合法性?ssl是如何加密数据的?
252
2023-08-17
让你的工作更高效!快来看看如何使用内网穿透
1179
2021-09-03
php怎么实现类的自动注册
1212
2021-07-23
golang 单元测试和性能测试
1106
2021-12-23
基于docker实现Redis集群(3主3从)
1464
2020-07-15
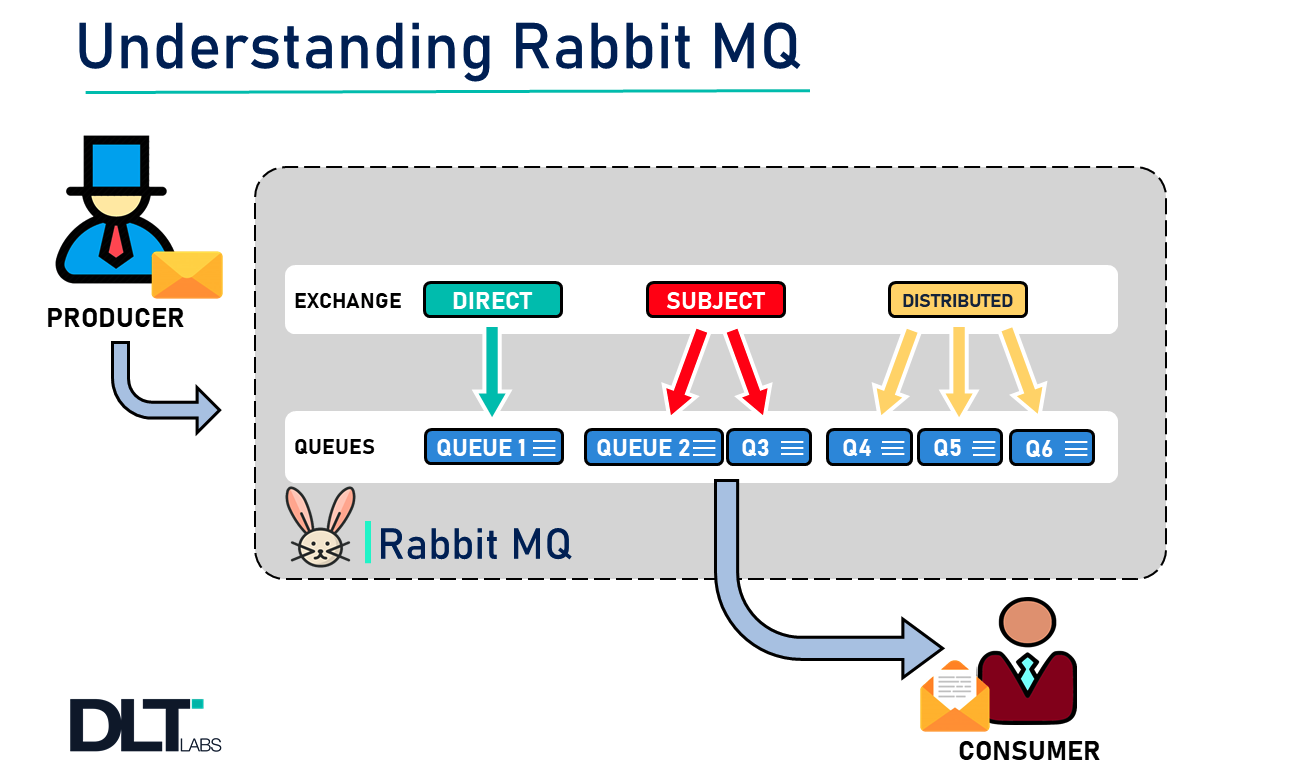
超详细的RabbitMQ快速入门!!你不拿走吗?
1225
2021-08-04
MySQL的内部XA的二阶段提交
121
2024-01-16

PHP孤儿进程、僵尸进程的代码演示和方法处理
1002
2022-03-01
易查网 资源共享 技术分享 phpstorm 激活码 网盘搜索 IDEA永久激活码_IDEA激活码2022和2023IDEA激活码,IDEA激活码 2022Pycharm激活码,Webstorm激活码 亲测有效 慕课网视频教程 慕课网基础教程
关注公众号 获取验证码
